SQL DB Reader
The SQL DB Reader plugin is deprecated, and no active development, new versions, or bug fixes are planned. It will reach end of life with the v14.0.0 of the console.
A microservice that can generically read all the DBs compatible with standard SQL queries.
Each profile defines the view on the DB and guarantees safety and reading flexibility.
It's a solution to integrate an existing database into the platform.
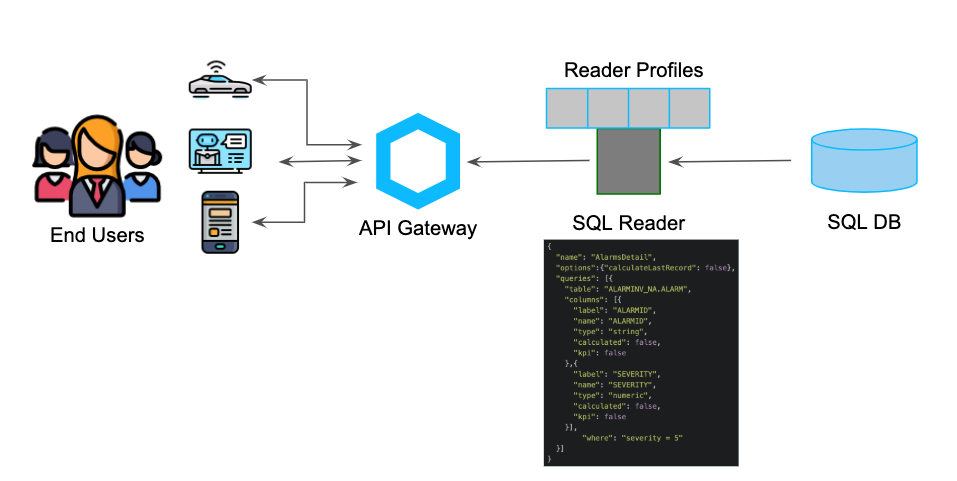
Profiles
To add a new profile create a new JSON file in the directory
profiles
rebuild and run the container. Every profile config JSON must have following fields:
name: The profile name. It must be equal to profile filename without extension specification.options: It's possible to specify some options, see below.queries: Queries that are effectively executed from service to DB. Currently are supported just one query profiles.
Profile requirements
- profile file must be JSON file
- profile file name must be equal to profile name
- profile must have one valid query set in queries array
- standard queries must have
tableandcolumnfield - standard queries must not have
directSqlfield - the
directSqlqueries must not havetable,column,group,where,having,order - scripted profile must have its own groovy script file
- groovy script file name must be equal to profile name
Profile Options
Each profile json has an options field like this.
{
"name": "profile_name",
"options":{
,
"isScripted": false,
"calculateTotal": true
},
"queries": [{...}]
}
Using this options it's possible to configure service behavior.
| option | values | default | description |
|---|---|---|---|
| calculateLastRecord | true, false | ? | ? |
| isScripted | true, false | false | If true will apply input and output customization using corresponding groovy script. |
| calculateTotal | true, false | true | If true will sequentially execute count query and add row count to result. If false it returns -1 as row count in result. |
Profile Queries
There are two kind of configuration, to set profile queries.
Standard query configuration
Standard query configuration includes the following fields
table: the SQL table name.columns: the SQL query projected columns.where: the SQL query where condition.order: the SQL query order conditions, it must be specified the column and the direction (DESC or ASC)
{
"name": "profile_name",
"options":{...},
"queries": [{
"table": "users",
"columns" : [
{"label": "name", "name": "name", "type": "string"},
{"label": "age", "name": "age", "type": "number"},
{"label": "gender", "name": "gender", "type": "string"},
],
"where" : "name = robert",
"order" : [{ "column": "age", "direction":"DESC" }]
}]
}
group: the SQL query group condition.having: the SQL grouped query having condition.
{
"name": "profile_name",
"options":{...},
"queries": [{
"table": "users",
"columns" : [
{"label": "name", "name": "name", "type": "string"},
{"label": "age", "name": "age", "type": "number"},
{"label": "gender", "name": "gender", "type": "string"},
{"label": "count", "name": "COUNT(*)", "type": "number"}
],
"group" : "age, name, gender",
"having" : "age > 10"
}]
}
Direct query configuration
Since v0.0.5 version it's possible to execute a direct SQL query, putting in directSql field inside profile configuration. In this case other field will be ignored.
{
"name": "profile_name",
"options":{...},
"queries": [{
"directSql": "SELECT * FROM users"
}]
}
Scripts
Each profile can have corresponding script to customize input query parameter and output ResultSet. Just set true the isScripted option and create a groovy script named like the profile.
Script requirements
Query parameters customization
- script must have
customizeQueryParamsmethod to customize http request query parameters. The method must have the following signature:
def customizeQueryParams(Map <String, Object> element) {
// do something
}
- if you want to skip query parameter customization just avoid to use method called
customizeQueryParams
Result db data extraction customization
- script must have
customizeDatamethod to customize db query result. The method must have the following signature:
def customizeData(Map <String, Object> element) {
// do something
}
- if you want to skip db query result customization just avoid to use method called
customizeData
Development
Build
mvn clean package
docker build -t nexus.mia-platform.eu/core/db-sql-reader .
Run from code
To run from source code
mvn spring-boot:run -Drun.arguments="--spring.config.location=src/main/resources/reader.properties"
Troubleshooting
- [Ubuntu 18.04] if you get the
java.sql.SQLException: ORA-01017: invalid username/password; logon deniedeven if your credentials are OK you can ssh yourself and launch command.
Build and Run locally (auto)
just run build-and-run-from-docker sh script from service root.
./scripts/build-and-run-beside-oracleDB.sh
Build and Run locally (manual)
Run SQL-Like DB (required)
To start this service a running sql-like db is required. Remember to set credentials in src/main/resources/reader.properties (see below)
Download or build your db image, run it with command like:
docker pull wnameless/oracle-xe-11g
docker run -d -p 1521:1521 wnameless/oracle-xe-11g
You can replace wnameless/oracle-xe-11g with any SQL-Like db compatible with jdbc.
Install DB driver (required)
You have to dowload the right driver for your database and configure it properly.
To install oracle driver
http://www.oracle.com/technetwork/database/features/jdbc/jdbc-drivers-12c-download-1958347.html
mvn install:install-file -DgroupId=com.oracle -DartifactId=ojdbc8 -Dpackaging=jar -Dversion=local -Dfile=lib/ojdbc8.jar -DgeneratePom=true
Configure reader.properties (required)
Put db credential and profile configuration in src/main/resources/reader.properties.
That's and example of valid properties use:
reader.application.name=Reader
reader.profiles.dir=profiles/devel
reader.driver=oracle.jdbc.driver.OracleDriver
reader.user=system
reader.password=oracle
reader.url=jdbc:oracle:thin:@//127.0.0.1:1521/xe
Query result mapping
Date Format
Use your own date format setting dateFormat in reader.properties file as follow:
reader.dateFormat=dd.MM.yyyy
Default value is ISO 8601 format.
Test
Unit Test
Just run
mvn test
to execute unit tests only.
Integration Test
Auto Run
just run from project root
bash scripts/run-integration-test.sh
and follow logs.
Manual Run
run from project root service instance and oracledb with
bash scripts/build-and-run-beside-oracleDB.sh
then just run with failsafe (build will succeed with test failures)
mvn failsafe:integration-test
or directly from your IDE.
Tests Coverage
| Test | File | Status |
|---|---|---|
| profile file must be a JSON file | ProfileBadConfig | OK |
| profile file name must be equal to profile name | ProfileBadConfig | OK |
| profile must have one valid query set in the queries array | ProfileBadConfig | OK |
| standard queries must have a table and column field | ProfileBadConfig | OK |
| standard queries must not have a directSql field | ProfileBadConfig | OK |
| directSql queries must not have table, column, group, where, having, order | ProfileBadConfig | OK |
| scripted profile must have its own groovy script file | ProfileBadConfig | OK |
| groovy script file name must be equal to the profile name | ProfileBadConfig | OK |
| directSql works | Query_Execution | OK |
| a standard query correctly selects columns | Query_Execution | OK |
| a standard query correctly applies where conditions | Query_Execution | OK |
| a standard query correctly applies having conditions | Query_Execution | OK |
| a standard query correctly applies order conditions | Query_Execution | OK |
| a standard query correctly applies groupBy conditions | Query_Execution | OK |
| interpolation is ok on a standard query with where conditions | Query_Execution | OK |
| interpolation is ok on a standard query with order conditions | Query_Execution | OK |
| interpolation is ok on a standard query with groupBy conditions | Query_Execution | OK |
| interpolation is ok on directSql | Query_Execution | OK |
| a query param customization on 'where' is applied correctly | Query_Customization | OK |
| a query param customization on 'directSql' is applied correctly | Query_Customization | OK |
| a result output customization from a standard query is applied correctly | Query_Customization | OK |
| a result output customization from directSql is applied correctly | Query_Customization | OK |
| settings on count | CountOrNot | OK |
| bind variables | BindVariables | OK |
Tag Project
Run script
Tag new project version
Please use the tag.sh to update the pom.xml project version and commit release to git.
Respect the following syntax to invoke the script:
bash tag.sh [options] [rc]
According to semver, options could be:
- major version when you make incompatible API changes
- minor version when you add functionality in a backwards-compatible manner
- patch version when you make backwards-compatible bug fixes.
According to Mia-Platform release process rc could be:
- rc add
-rcto your release tag - omitted
Promote rc release
When your service is ready to production you can promote your rc version invoking the script with promote option.
bash tag.sh promote
Push changes
Don't forget to push commit and tag:
git push
git push --tags
Examples
Assuming your current version is v1.2.3
| command | result |
|---|---|
bash tag.sh major | v2.0.0 |
bash tag.sh minor | v1.3.0 |
bash tag.sh patch | v1.2.4 |
bash tag.sh major rc | v2.0.0-rc |
bash tag.sh minor rc | v1.3.0-rc |
bash tag.sh patch rc | v1.2.4-rc |
Assuming your current version is v1.2.3-rc
| command | result |
|---|---|
bash tag.sh promote | v1.2.3 |