Configuration files
The Real-Time Updater has a variety of configurations: some of them are automatically managed by the MIA Console, while others can be configured by the user either using Config Maps or No-Code features.
Message Adapters
In the Fast Data architecture CDC, iPaaS, APIs and sFTP publish messages on Kafka topic to capture change events. However, these messages could be written in different formats. The purpose of the Kafka adapter is allowing the correct reading of these messages in order to be properly consumed by the Real-Time Updater.
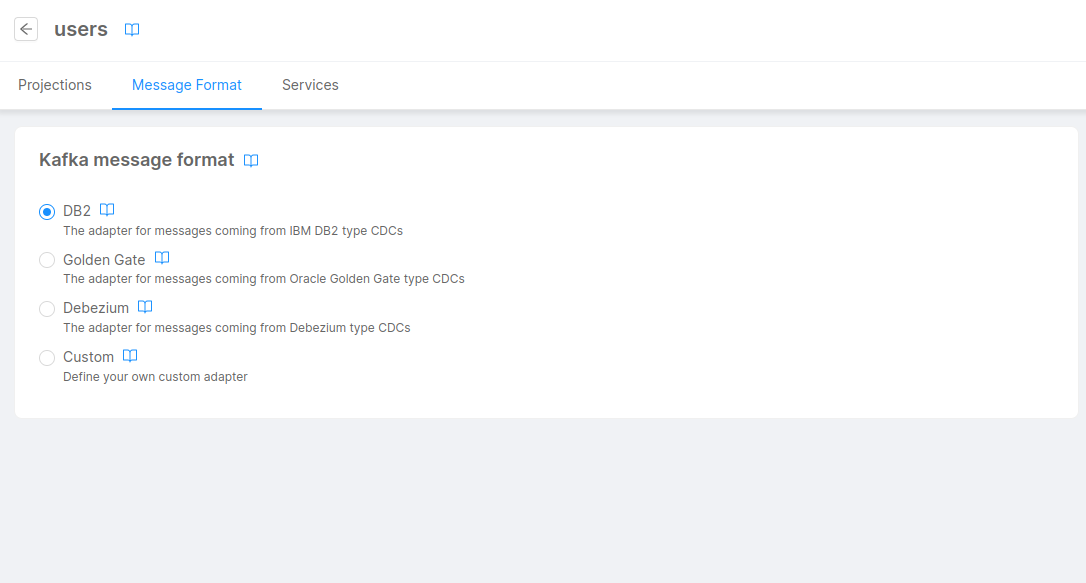
Since one or multiple Real-Time Updater services could be connected to a System of Record, when creating a new System you will be asked to select the type of message adapter you want to use, between one of the following options (further details in the paragraphs below):
DB2, based on the IBM InfoSphere Data Replication for DB2 type CDC;Golden Gate, based on the Oracle GoldenGate type CDC;Debezium, based on the Debezium type CDC;Custom, in case you need a completely customized message adapter (you'll be requested to write the implementation code);
The selection will be applied to every Real-Time Updater service attached (or to any service that will be attached in the future) to ensure that those service will be expecting messages in the correct type.
In case you need to change the type of adapter to use in the Real-Time Updater, you can easily do that from the System of Record page in the Projection section of the console: after selecting your System, click on the Message Format tab, then select the adapter type you want to use.
IBM InfoSphere Data Replication for DB2
It's the default one, it is based on the IBM InfoSphere Data Replication engine.
The message should include the following properties:
timestamp: a stringified integer greater than zero. This integer has to be a valid timestamp.key: it has to be a stringified object containing the primary key of the projection, ifvaluealso contains the primary key of the projection this field can be an empty string.value: it is null if it's a delete operation, otherwise it contains the data of the projection.offset: it is the offset of the Kafka message.
It is important to note that whenever the ingestion message is not a delete operation the value of the message must contain all the fields of the projection, including the primary keys also present in the key, so the Real-Time Updater can process the message properly.
These are the only fields needed to configure correctly the message adapter. For more details and further explanations, you can read the documentation page about the supported JSON format.
To see the message's structure specification and some examples go to the Inputs and Outputs page .
This Kafka message format does not support a Primary Key update. For additional information, please check the Primary Key update section.
Oracle GoldenGate
This Kafka Message Adapter has been created to have a format supported by Oracle Golden Gate.
In this Golden Gate adapter, we expect that the message includes data as explained in the JSON Formatter page of the official documentation.
To see the message's structure specification and some examples go to the Inputs and Outputs page .
Debezium
The Debezium kafka message adapter is meant to accept Debezium generated kafka messages with the following properties:
- before: optional value that indicates the data values before the operation execution
- after: optional value that indicates the data values after the operation execution
- op: optional value that indicates the type of operation,
cfor create/insert,ufor update anddfor delete
These are the main properties used by the adapter and the Real-Time Updater but you can have other properties like ts_ms or source depending on which DB is Debezium working with.
Debezium has also some "special" events which are handled in their own way:
- Snapshot: Snapshot events are messages that indicate the state of the DB up until that point in time. This messages are sent when the connector does not find any offsets from where to start processing, therefore they are handled as normal insert messages.
- Tombstone: Tombstone events are messages sent after a normal delete message and are only useful for kafka itself and its topic compression policies. For this reason the adapter will ignore and skip them.
- Truncate: Truncate events are messages sent when an entire table is emptied. Unfortunately we do not support this kind of messages at the moment and they will be skipped.
To see the message's structure specification and some examples go to the Inputs and Outputs page .
Custom
If you have Kafka Messages that do not match one of the formats above, you can create your own custom adapter for the messages.
To make this work, you need to create a Custom Kafka Message Adapter inside Real-Time Updater section of the related System of Record. The adapter must be a javascript function that converts Kafka messages as received from the Real-Time Updater to an object with a specific structure. This function must receives as arguments the Kafka message and the list of primary keys of the projection, and must return an object with the following properties:
- offset: the offset of the Kafka message
- timestampDate: an instance of
Dateof the timestamp of the Kafka message. - keyObject: an object containing the primary keys of the projection. It is used to know which projection document needs to be updated with the changes set in the value.
- value: the data values of the projection, or null
- operation: optional value that indicates the type of operation (either
Ifor insert,Ufor update, orDfor delete). It is not needed if you are using an upsert on insert logic (the default one), while it is required if you want to differentiate between insert and update messages. - before: optional value that indicates the data values before the operation execution
- after: optional value that indicates the data values after the operation execution
- operationPosition: optional value that indicates a positive integer, usually a timestamp, which ensures messages are processed in the correct order
If the value is null, it is a delete operation.
The keyObject cannot be null.
To see the message's structure specification and some examples go to the Inputs and Outputs page .
To support a Primary Key update, the before, after and operationPosition fields should be included in the adapter. (Hint: if not present, a simple operationPosition value might be the Kafka message timestamp).
Inside configmap folder create your javascript file named kafkaMessageAdapter.js.
The file should export a simple function with the following signature:
module.exports = function messageAdapter(message, primaryKeys, logger) {
const {
value: valueAsBuffer, // type Buffer
key: keyAsBuffer, // type Buffer
timestamp: timestampAsString, // type string
offset: offsetAsString, // type string
} = message
// your adapting logic
return {
keyObject: keyToReturn, // type object (NOT nullable)
value: valueToReturn, // type object (null or object)
timestampDate: new Date(parseInt(timestampAsString)), // type Date
offset: parseInt(offsetAsString), // type number
operation: operationToReturn, // type string (either I, U, or D)
}
}
The message argument is the Kafka message as received from the real-time-updater.
The fields value and key are of type Buffer, offset and timestamp are of type string.
The primaryKeys is an array of strings which are the primary keys of the projection whose topic is linked.
Starting from v7.8.0, the Real-Time Updater can accept a message adapter written as a default ESM module.
export default function myEsmMessageAdapter(message, primaryKeys, logger) {
// ...adapter logic
}
This definition is also supported by versions v6.1.0 and v.5.5.0.
Kafka Projection Updates Configuration
Whenever the Real-Time Updater performs a change on Mongo on a projection, you can choose to send a message to a Kafka topic as well, containing information about the performed change and, if possible, the state of the projection before and after the change and the document ID of the document involved in the change.
This feature has been introduced since version v3.5.0 of the Real-Time updater
To activate this feature you need to set the following environment variables:
KAFKA_PROJECTION_UPDATES_FOLDER: path to the folder that contains the filekafkaProjectionUpdates.json, containing configurations of the topic where to send the updates to, mapped to each projection.GENERATE_KAFKA_PROJECTION_UPDATES: defines whether the Real-Time Updater should send a message of update every time it writes the projection to Mongo. Default isfalse
From v10.2.0 of Mia-Platform Console, a configuration for Kafka Projection Updates is automatically generated when creating a new Real-Time Updater and saving the configuration. Further information about the automatic generation can be found inside the Projection page. If you prefer to create a custom configuration, please use the following guide.
You need to create a configuration with the same path as the one you set in KAFKA_PROJECTION_UPDATES_FOLDER. Then, you have to create a configuration file kafkaProjectionUpdates.json inside that configuration.
To prevent possible conflicts with the automatically created configuration, please set the KAFKA_PROJECTION_UPDATES_FOLDER to a value different from the default /home/node/app/kafkaProjectionUpdates path.
To know more on how to configure the kafkaProjectionUpdates.json please refer to its Configuration page.
Notice that you can either set the topics for all the projections, or for a subset of them. So, for example, if you need to setup a Single View Patch operation, you may want to configure only the projections needed in such Single View.
ER schema configuration
The ER Schema, defined with a erSchema.json file, defines the relationship between tables and projections. On the dedicated page in the Config Map section, you can find a deep explanation of how ER Schema configuration works.
You can update the ER Schema in the page of the Real-Time Updater, in the ConfigMaps & Secrets page.
The ER Schema ConfigMap is created after the service is attached to a System of Record for the first time. It will include base erSchema.json file is generated with the following content:
{
"version": "1.0.0",
"config": { }
}
This is an empty configuration: the Real-Time Updater Microservice could be deployed without pod restart, but this file must be modified according to the projections associated with this microservice to work properly.
If you have already attached an ER Schema to a Single View Creator, you can re-use it in the Real-Time Updater configuration too.
By deleting the default one and add an existing ER Schema Config Map with a mount path as the one provided in the ER_SCHEMA_FOLDER environment variable, changes made to an Er Schema will be reflected also in the Real-Time Updater.
While this solution provides reusability of other ER Schemas, is strongly suggested to use the No Code.
Projection Changes Schema
The projectionChangesSchema.json config map defines the paths for the strategy to generate the projection changes identifier. Differently from the Manual Configuration, the projection changes configurations are described with a JSON file aimed to reduce the developing effort.
The Projection Changes Schema ConfigMap is created after the service is attached to a System of Record for the first time.
It will include base projectionChangesSchema.json file is generated with the following content:
{
"version": "1.0.0",
"config": { }
}
This is an empty configuration: the Real-Time Updater Microservice could be deployed without pod restart, but this file must be modified according to the projections associated with this microservice to work properly.
For more information please refer to the Projection Changes Schema dedicated page.
CAST_FUNCTION configurations
The mount path used for these configurations is: /home/node/app/configurations/castFunctionsFolder.
In this folder you have all the generated Cast Functions definitions. This configuration is read-only since you can configure it from its dedicated section of the Console.
Starting from v7.8.0, the Real-Time Updater can accept a cast function having the new signature, which accepts the whole ingestion message as first parameter and it's defined as a default ESM module.
export default function myNewCastFunction(messageObject, fieldName, logger) {
return messageObject[fieldName];
}
This definition is also supported by versions v6.1.0 and v.5.5.0.
MAP_TABLE configurations
The mount path used for these configurations is: /home/node/app/configurations/mapTableFolder.
Two mappings will be placed in this folder:
- one between cast functions and fields;
- one between strategies and projections.
This configuration is read-only since it's configured automatically based on the projections of the System of Record included in the attached service and the strategies you configure from the Single Views section of the Console.
Send Projection Changes to Kafka
This feature is deprecated and will be removed in future versions of the Real-Time Updater service. In case you need the service to send events to Kafka, follow the configuration of Kafka Projection Updates.
Projection changes are saved on Mongo, but from version v3.4.0 and above, you can send them to Kafka as well.
This feature enables you to send the projection changes to a topic Kafka you want to. This is useful if you want to have a history of the projection changes thanks to the Kafka retention of messages. You can also make your own custom logic when a projection change occurs by setting a Kafka consumer attached to the topic Kafka you set.
To do that, you need to set two environment variables:
GENERATE_KAFKA_PROJECTION_CHANGES: defines whether the projection changes have to be sent to Kafka too or not. Default isfalse(v3.4.0 or above).KAFKA_PROJECTION_CHANGES_FOLDER: path where has been mounted thekafkaProjectionChanges.jsonconfiguration (v3.4.0 or above).
You have to create a configuration with the same path as the one defined by the environment variable KAFKA_PROJECTION_CHANGES_FOLDER.
Then, you have to create a configuration file kafkaProjectionChanges.json inside that configuration. The configuration is a json file like the following one:
{
"MY_PROJECTION": {
"projectionChanges": {
"MY_SINGLE_VIEW": {
"strategy": "MY_STRATEGY",
"topic": "MY_TOPIC",
}
}
}
}
where:
MY_PROJECTIONis the name of the collection whose topic has received the message from the CDC.MY_SINGLE_VIEWis the single view that have to be updatedMY_STRATEGYis the strategy to be used to get the identifier of the Single View to update. It could be the name of a file or, in case an automatic strategy, the string__automatic__.MY_TOPICis the topic where the projection change need to be sent (for further information about the naming convention adopted for this topic, click here)
Example
{
"registry-json": {
"projectionChanges": {
"sv_pointofsale": {
"strategy": "__automatic__",
"topic": "my-tenant.development.my-database.sv-pointofsale.projection-change",
}
}
},
"another-projection": {
"projectionChanges": {
"sv_customer": {
"strategy": "__fromFile__[myStrategy]",
"topic": "my-tenant.development.my-database.sv-customer.projection-change"
}
}
}
}
When a message about registry-json happens, the projection changes will be saved on MongoDB, and it will be sent to the Kafka topic my-tenant.development.my-database.sv-pointofsale.projection-change as well.