Bucket Storage Support
The Bucket Storage Support enables storing messages flowing through a channel into an external storage system, such as a Google Cloud Storage bucket or any bucket compatible with Amazon AWS S3 interface.
What We Will Build
In this tutorial, you will configure a Console Project containing the Bucket Storage application, that will store data coming from Kafka ingestion topics. In particular, you will:
- Create the microservices of the Bucket Storage Support solution;
- Configure ingestion-topics and store the incoming message in a sequence of batch text files in a dedicated bucket folder;
- Expose an endpoint to reload the data from the bucket files into a dedicated re-ingestion topic.
Prerequisites
- Knowledge of Fast Data architecture and Bucket Storage Support.
- An up-and-running Kafka cluster.
- Either GCP or S3-like bucket connection.
Setup the Microservices
The Bucket Storage Support can be either configured for GCP Bucket or S3 Bucket, and it provides two microservice:
- Ingestion Storer, to configure with ingestion-topics that will be stored in the corresponding bucket folder
- Ingestion Reloader, a REST microservice that will use bucket's SDK to produce message into a topic, usually referred to as re-ingestion topic, specified by the incoming request.
You can create this microservices as plugins starting directly from the Console Marketplace, or either create an Application, choosing between S3-like bucket or GCP bucket.
The configuration steps will let you create, besides the two microservices with their respective configurations, the following resources:
status-service: a CRUD collection used by the Ingestion Reloader to keep track of the requests to perform re-ingestion of the data- API Gateway endpoints to:
- expose with the CRUD Service the aforementioned collection;
- expose the endpoints of the Ingestion Reloader.
- public variables such as:
- BUCKET_NAME: the name of the bucket that will be used by Bucket Storage Support applications;
- INGESTION_RELOADER_CLIENT_ID: the Kafka client id used by the Ingestion Reloader;
- INGESTION_STORER_CLIENT_ID: the Kafka client id used by the Ingestion Storer;
- KAFKA_STORER_GROUP_ID: the kafka consumer group id used by the Ingestion Storer to read messages from ingestion topics;
- BSS_EVENTS_TOPIC: name of the topic that will be used by the Ingestion Storer to publish events related to files written into the bucket.
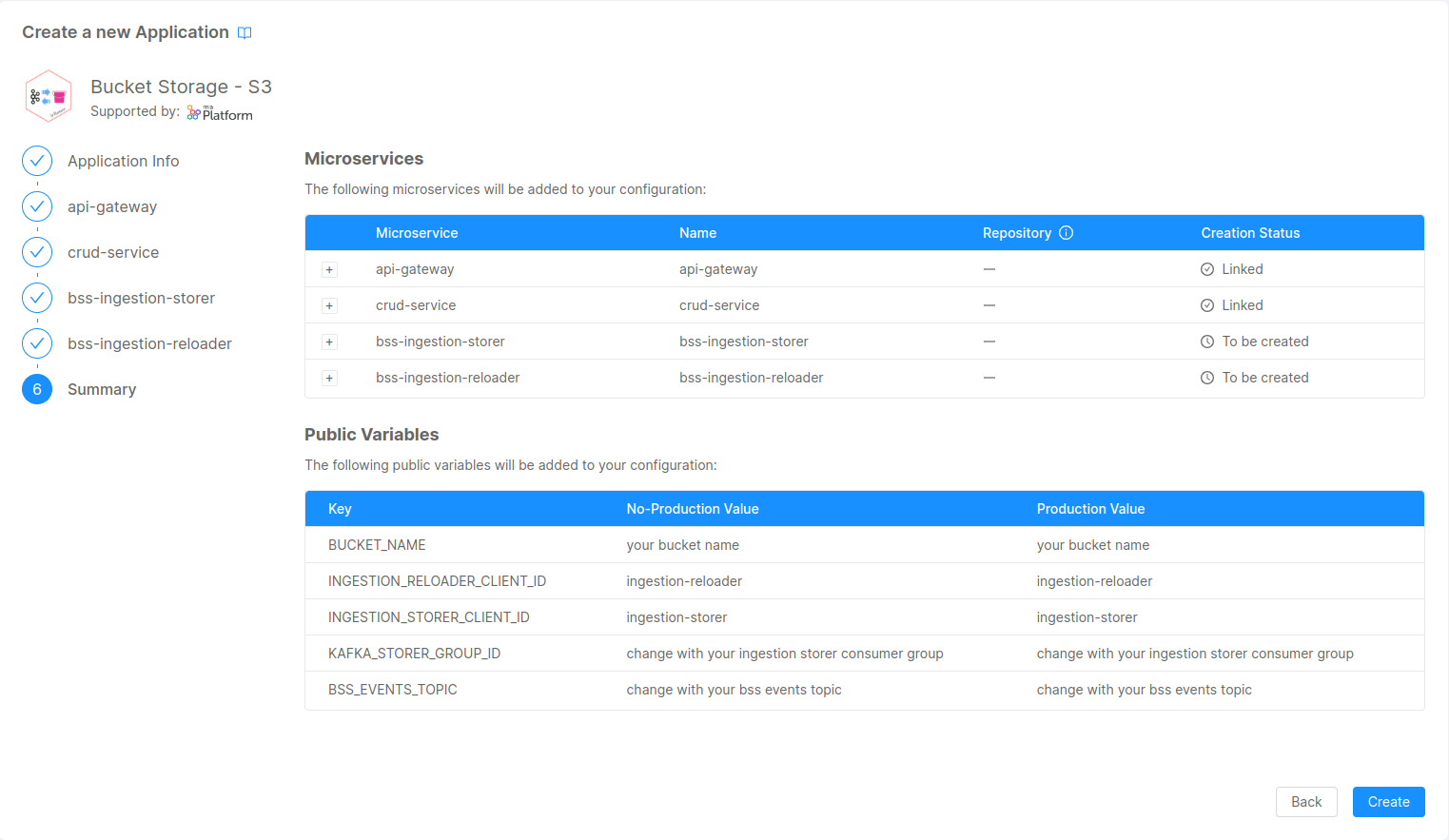
Public variables must be changed according to the environment you're releasing the Bucket Storage Support. In particular, during this tutorial, you'll have to check the messages that will be produced to the BSS_EVENTS_TOPIC during the section Testing Ingestion.
Setup the Bucket connection
If you choose the Application, you will still have to do some manual operations to setup the connection to the bucket. For more details about the bucket connections, visit the related section in the Bucket Storage Support page.
Setup the Kafka Connection
You need also to setup the parameters to let the new microservices connect to your Kafka Cluster. For more details about kafka connections, visit the related section in the Bucket Storage Support page. For basic connections, you'll just need to define the following variables:
- KAFKA_BROKERS: the list of the kafka brokers that will host both ingestion and re-ingestion topics;
- KAFKA_SASL_USERNAME: the username that will be used to login to the kafka brokers;
- KAFKA_SASL_PASSWORD: the password that will be used to login to the kafka brokers;
- KAFKA_SASL_MECHANISM: the mechanism that will be used to login to the kafka brokers. (default is
SCRAM-SHA-256)
Data Ingestion
An ingestion topic is a queue from your Kafka broker that represents the data source that we want to store in the bucket.
The messages sent to this queue are not bound to a specific format: the Ingestion Storer will create text files containing line-separated json messages stringified.
Once the microservices are configured, we can start to overwrite the application.yaml configuration of the Ingestion Storer to define the ingestion topics. Lets the consider the Registry Projection from the Fast Data tutorial. Here's the basic configuration that you will have to provide:
bss:
topics-config:
data-topics-mapping:
- ingestion: demo.<environment>.delivery.registry.ingestion
post-ingestion: []
In this way, you are telling the Ingestion Storer to register its consumer group to the topic demo.<environment>.delivery.registry.ingestion, where <environment> should be replaced with the environment you need to deploy the Bucket Storage Support solution.
Please note that the post-ingestion array is set to empty: this is to make the bucket storage support independent from other possible data flows that are using ingestion topics, such as the Fast Data.
If you set a list of post ingestion topics, then the Ingestion Storer will also replicate the messages to the topics defined in the post-ingestion field.
Testing Ingestion
Now it's time to save and deploy the new configuration.
After that, we can try to send messages to the Registry Kafka Topic from in the previous step and see if messages are correctly stored by the Ingestion Storer into the bucket.
Let's consider a basic case where the following registries are published to the ingestion topic.
Click to see the ingestion messages:
Ingestion messages generally has a specific format, as defined in the Inputs and Outputs section of the Fast Data.
For the sake of simplicity, in this tutorial the ingestion messages contains only the payload of a projection. It's worth noting that the Ingestion Storer does not perform any validation on the input message, which can be of any JSON format.
If you check the incoming messages from the topic defined inside the variable BSS_EVENTS_TOPIC, you should see a kafka message sent by the ingestion storer with the following key-value format:
-
the key of the message is a JSON object formatted as follows:
{ "partition": 1, "topic":"demo.<environment>.delivery.registry.ingestion" } -
value:
{"batchOffsetEnd": 7,"batchOffsetStart": 5,"batchSize": 3,"batchTimeEnd": "2023-06-23T09:13:00.000Z","batchTimeStart": "2023-06-23T09:10:00.702Z","filePath": "demo.<environment>.delivery.registry.ingestion/2023-06-23T09:10:00.702Z_demo.<environment>.delivery.registry.ingestion_0_5_<timestamp>.txt"}Let's see in details the different information of the JSON message:
batchSizetells the number of messages that have been stored into the filebatchOffsetStartandbatchOffsetEndare respectively the beginning and the end of offsets representing the offset's boundaries of message in the partition written to the file;batchTimeStartandbatchTimeEndare respectively the beginning and the end of iso-formatted timestamp representing the time boundaries of messages in the partition written to the file;filePathdenotes the result written in the bucket and has the following format:"<topic_name>/<topic_name>_<partition>_<batchOffsetStart>_<timestamp>.txt"Before starting to create projections, we need to create the System of Record (SoR) representing the source system we want to connect to.
Data Re-Ingestion
Once the data is stored in the bucket, it can be processed later again to manage different use cases, as explained in this section. This process is referred to as re-ingestion.
Based on the different needs where Bucket Storage is deployed, two types of re-ingestions procedures can be applied using the Ingestion Reloader. You can see its APIs available in the API Documentations
Messages loaded in the bucket are sent to a topic specified in the client's request, and is referred to as reIngestionTopic. If we consider the Registry Projection, you can use the following topic suggestion demo.<environment>.delivery.registry.reingestion, where <environment> is the name of the environment where you are gonna to deploy the bucket storage support.
You can re-ingest the messages contained in the file that was written in the bucket after the ingestion of the message from the previous section.
- File Re-Ingestion
- Topic Re-Ingestion
You can perform the following POST request to the /reingestion/file endpoint:
curl -X POST 'https://<your-project-domain>/reingestion/file' \
-H 'Content-Type: application/json' \
-d '{
"fileName": "demo.<environment>.delivery.registry.ingestion/2023-06-23T09:10:00.702Z_demo.<environment>.delivery.registry.ingestion_0_5_<timestamp>.txt",
"reIngestionTopic": "demo.<environment>.delivery.registry.reingestion"
}'
For more information on the usage of the file re-ingestion endpoint, please refer to this section.
You can re-ingest all the messages from all files contained inside a whole folder related to an ingestion topic.
To achieve this, you can perform the following POST request to the /reingestion/topic endpoint:
curl -X POST 'https://<your-project-domain>/reingestion/topic' \
-H 'Content-Type: application/json' \
-d '{
"topic": "demo.<environment>.delivery.registry.ingestion/2023-06-23T09:10:00.702Z_demo.<environment>.delivery.registry.ingestion_0_5_<timestamp>.txt",
"reIngestionTopic": "demo.<environment>.delivery.registry.reingestion"
}'
'
The response is the same as the re-ingest file request. For more information on the usage of the folder re-ingestion endpoint, please refer to this section.
Testing Re-Ingestion
The Ingestion Reloader will answer with a status code 202 response containing the following JSON body:
{
"requestId": "638f4fd76a90e7a1510adb09",
"message": "Reingestion started"
}
You can later use the content of the field requestId to retrieve from the Status Service CRUD collection created before the status of the request. This means performing the following GET request:
curl -X GET 'https://<your-project-domain>/status-service/638f4fd76a90e7a1510adb09'
The CRUD Service will return the following object:
{
/** CRUD service required fields */
"request": {
"fileName": "demo.<environment>.delivery.registry.ingestion/2023-06-23T09:10:00.702Z_demo.<environment>.delivery.registry.ingestion_0_5_<timestamp>.txt",
"reIngestionTopic": "demo.<environment>.delivery.registry.reingestion"
},
"lineIndex": 3,
"status": "COMPLETE",
}
where:
lineIndexrepresents the number of message published to the re-ingestion topic;statuscan be eitherSTART,COMPLETE,STOPPED,ERROR
You can check also on the re-ingestion topic that the published messages reflects the ingestion messages created before.