Create a RAG Application
In this tutorial, you will learn how to create a fully functioning RAG application in a Mia-Platform project in just a few minutes. We will cover the setup of the necessary services and the operations required to have a chatbot that is ready to assist and provide help on specific topics based on the documents provided.
To accomplish this, you will utilize the Marketplace application called AI RAG Chat. This application includes:
- the RAG Chatbot API service, which leverages the APIs provided by OpenAI or Azure OpenAI to receive answers to questions in natural language, and to create embeddings, encoded definitions coming from pieces of text extracted from a website.
- the AI RAG Template Chat service, a small frontend application written in React that provides a simple chat interface to communicate with the chatbot.
- the API Gateway service, that will be used to expose the endpoints to reach the frontend application and communicate with the service.
- several endpoints to expose the necessary APIs from the services to use the application.
The RAG Chatbot API is a ready-to-use Plugin maintained and supported by Mia-Platform that includes all the necessary logic to build a fully functional RAG application.
However, if you need to deep-dive into the code by yourself, to create a more suitable and customized application, you can use the AI RAG Chat Template application instead. The AI RAG Chat Template application includes all the features above, but creates a clone of the AI RAG Template repository in your provider to allow you to customize it accordingly to your needs.
Furthermore, you will install the API Documentation Aggregator application and the API Portal from the templates. These will enable us to easily send HTTP requests to the RAG Chatbot API service to store additional documents in a database in a way that can be used by the service to answer questions.
The prerequisites for this tutorial are as follows:
- A connection string to a MongoDB Atlas instance (unfortunately, MongoDB on-premise installations do not currently support the Vector Search Index, required for this process).
- One of the following:
- if you want to use OpenAI as a provider, an API key to communicate with OpenAI
- if you want to use Azure as a provider, a functioning deployment of both an Embedding model and a Large Language Model (you can find more information on how to do this in the related documentation).
How it works
RAG stands for Retrieval-Augmented Generation, and it is a process to enhance the knowledge of a LLM (large language model), which is an algorithm capable of generating text in natural language. The goal of RAG is to create applications that can communicate with users and answer questions related to specific topics.
To understand how RAG works, let's consider an example. Imagine you want to create a chatbot that can answer questions about the internal documentation of the product your company sells. Imagine this documentation is hosted in a website, just like this documentation. It can be extensive, consisting of multiple files. To handle this large amount of text, it can be divided into smaller pieces called chunks. These chunks can be split in various ways, such as by paragraph, by page, or by the semantic meaning of the text. Each chunk can then be transformed into a single document and stored in a database.
This will allow to compare the question asked by a user with the text saved in the database. In order to efficiently retrieve documents from the database, it is need to find a reliable method to compare the meaning of the question with the meaning of the chunks to be used. To achieve this, embeddings can be created: the text is given to a mathematical model that will generate a multidimensional vector composed of hundreds of values between 0 and 1, effectively representing the meaning of the text. Then, these embeddings will saved in the database along with the chunk of text used to create them.
By doing this, whenever our chatbot receives a question, it is possible to:
- Generate embeddings from the question.
- Search the database for documents with embeddings that are similar in meaning to the embeddings of the question.
- Retrieve the matched documents and use their text to ensure that the chatbot provides an appropriate answer.
OpenAI has several embedding models (that can be also deployed using Azure AI Foundry), and MongoDB proposes the Vector Search Index to efficiently search in a database for documents where embeddings are similar in meaning to our question.
Since embeddings are stored in a database, it is not required to generate them every time the service starts or a question is asked. However they should be replaced with new embeddings when the documents (e.g. our the internal documentation of our product) receive important updates. There are several methods to generate these embeddings.
If the documentation is available on a website, the most common and straightforward approach is to perform web scraping. This involves downloading all the pages of the website, recursively fetch all the other pages from the same website connected by hyperlinks, then removing any unnecessary information such as HTML tags, headers, footers, and styles, and generating embeddings from the remaining text. The RAG Chatbot API is a perfect example of a tool that can perform all these operations. It provides automatic connections to the Azure/OpenAI servers and the MongoDB database, allowing for seamless handling of Vector Indexes. Additionally, it can generate embeddings by simply providing a URL. With this template, creating a RAG application can be done in just a few minutes.
Another approach to generate embeddings is to start from internal documents, that you might have in form of a text file, a PDF file or multiple files in an zip archive. The RAG Chatbot API includes another endpoint where a file can be uploaded, and the embeddings will be generated automatically from the content of the file.
1. Install the required applications
From a new project, you will create two applications: the API Documentation Aggregator and the AI RAG Chat.
To begin, navigate to the design section and click on Applications in the sidebar. Then, select Create new Application.
First, search for and select the API Documentation Aggregator. This will install the API Gateway and the Swagger Aggregator, along with several endpoints to expose the Swagger UI for viewing the APIs exposed by the configured services and retrieving the OpenAPI compliant schema.
The API Documentation Aggregator is not required for the chatbot to function, but it is recommended for using the RAG Chatbot API APIs to generate the embeddings. You can also refer to the instructions in this tutorial.
Next, proceed to set up the application. When searching in the marketplace, search for AI RAG Chat. You can find two different results:
- the AI RAG Chat, which is the application where the RAG Chatbot API is provided in form of a Plugin, maintained and supported by the Mia-Platform team
- the AI RAG Chat Template, which is the application where the RAG Chatbot API is provided in form of a Template that will create a repository in your Git provider; while this template represents all the features of the plugin and it is fully functional, you can modify it by adding or removing features according to your needs
It will prompt you to create the API Gateway (you can use the previously created one with the available listener), the RAG Chatbot API, and the AI RAG Template Chat, along with several endpoints to expose the service APIs for sending questions and generating embeddings.
Finally, create the API Portal. If it is not already included in the project, navigate to the Microservices section, and then select Create new microservice. Choose From Marketplace, and on the following page, search for and create a new API Portal.
Once you have created these services, you can safely save the configuration.
2. Configure the RAG Chatbot API service
The next step is to configure the RAG Chatbot API service. From the design section, navigate to the Microservices page and select the service (the default name is rag-chatbot-api, but you may have changed its name). From there, click on the Environment Variables tab where you need to modify the following values:
MONGODB_CLUSTER_URI: This is the full connection string to MongoDB (refer to the official MongoDB documentation to find it).EMBEDDINGS_API_KEY: An API key to use when communicating with the provider for generating embeddings.LLM_API_KEY: An API key to use when communicating with the provider for generating responses.
EMBEDDINGS_API_KEY and LLM_API_KEY will have the same value unless you use OpenAI for one model and Azure for another.
Remember that you can generate API keys from the OpenAI Developer Dashboard or the Azure Portal.
To ensure this information remains secure, it is recommended to include it as project variables.
After updating the environment variables of the RAG Chatbot API service, it is time to update the config map: click on the ConfigMaps & Secrets tab and you will be redirected to the Config Map configuration page.
The RAG Chatbot API is created with a precompiled config map that includes all the required keys, but the values need to be included.
Here is an example of what the configuration should look like:
{
"llm": {
"type": "openai",
"name": "gpt-4o-mini"
},
"embeddings": {
"type": "openai",
"name": "text-embedding-3-small"
},
"vectorStore": {
"dbName": "rag-database",
"collectionName": "rag-collection",
"indexName": "vector_index",
"relevanceScoreFn": "cosine",
"embeddingKey": "embedding",
"textKey": "text",
"maxDocumentsToRetrieve": 3
}
}
More specifically, here is a detailed list of the meaning of each property:
- the
llm.typekey is the LLM provider, could beazureoropenai(default isopenai) - the
llm.namekey is the LLM model among those available from OpenAI, suggested aregpt-4oandgpt-4o-mini - the
embeddings.typekey is the Embedding provider, could beazureoropenai(default isopenai) - the
embeddings.namekey is the Embedding model used to generate embeddings, among those available from OpenAI, the suggested istext-embedding-3-small - the
vectorStore.dbNameis the name of the database where the embeddings will be saved - the
vectorStore.collectionNameis the name of the collection where the embeddings will be saved - the
vectorStore.indexNameis the name of the MongoDB Search Vector Index, withvector_indexas suggested name; this is a particular index that the service will automatically create or update at the startup - the
vectorStore.relevanceScoreFnis the name of the similarity search function used to retrieve the embedding documents; MongoDB includes three different available functions:cosine(suggested),euclideananddotProduct - the
vectorStore.embeddingKeyis the name of the field where the embeddings of a single document are saved, in the shape of a multidimensional array; we suggest using the default valueembedding - the
vectorStore.textKeyis the name of the field that contains the original text used to be transformed into embeddings, and that will be used to help the chatbot return the answer; we suggest using the default valuetext - the
vectorStore.maxDocumentsToRetrieveis the maximum number of documents that will be extracted and used to help the chatbot return the answer; the default value is3, but it is usually suggested to use a value between2and5, depending on how big the collection of the embeddings is (if the content is small then2would be more than enough; on the other hand if there is a lot of content is better to set this value to5)
After having configured the config map, you can save the configuration and move to the deploy.
Here is an example of a valid configuration where both the embedding model used and the large language model used comes from Azure OpenAI:
{
"llm": {
"type": "azure",
"name": "gpt-3.5-turbo",
"deploymentName": "dep-gpt35-turbo",
"url": "https://my-endpoint.openai.azure.com/",
"apiVersion": "2024-05-01-preview"
},
"embeddings": {
"type": "azure",
"name": "text-embeddings-3-small",
"deploymentName": "dep-text-embeddings-3-small",
"url": "https://my-endpoint.openai.azure.com/",
"apiVersion": "2024-05-01-preview"
},
"vectorStore": {
...
}
}
Additionally to what we have seen before, the configuration must also include:
- if the
llm.typeisazure, then it is also required to add:- the
llm.deploymentNamekey, which is the name of the deployment of the LLM - the
llm.urlkey, which is the endpoint of the LLM - the
llm.apiVersionkey, which is the API version of the LLM
- the
- if the
embeddings.typeisazure, then it is also required to add:- the
embeddings.deploymentNamekey, which is the name of the deployment of the Embedding - the
embeddings.urlkey, which is the endpoint of the Embedding - the
embeddings.apiVersionkey, which is the API version of the Embedding
- the
The content of vectorStore is the same as the one described in the previous section.
3. Deploy the configuration and generate embeddings
From the deploy section, you can deploy the new configuration. After verifying that the services are up, we can check if the application is running by accessing the chatbot frontend.
The frontend is accessible through the automatically generated endpoint / (e.g., if the project is hosted at https://my-project.console.my-company.com, the frontend will be accessible at the same URL).
The frontend will display a page with an input field where you can communicate with the chatbot. However, at this point, there are no embeddings, so specific questions may not give us the expected response.
To see the list of all the APIs exposed by the configured services, you can go to the swagger UI of the API Portal. It can be accessed at the endpoint /documentations/api-portal.
In the list of APIs, you will find three APIs with the tag Embeddings:
POST api/embeddings/generateto generate embeddings from a webpagePOST api/embeddings/generateFromFileto generate embeddings from a fileGET api/embeddings/statusto check the status of the generation process
The POST api/embeddings/generate API allows us to generate embeddings starting from a webpage.
The service will download the page, extract all the text, and generate embeddings from it.
It will also search for links on the page and recursively generate embeddings from the linked pages that have the same domain and follow the specified filter path.
The embeddings generation, either from website or from file, can take a while.
Because of this, it is an asynchronous task, meaning that the API response is returned immediately, but the generation process continues in the background.
To check the status of the generation process, you can use the GET api/embeddings/status API:
- If the response is
{"status": "running"}, it means the process is still ongoing. - If the response is
{"status": "idle"}, it means there are no active processes at the moment (indicating that the previous process has finished).
The process may take a few seconds to several minutes, depending on how much content from the webpages or the files need to be downloaded and scraped. It is a good idea to check the service logs of the pod to ensure that everything is progressing smoothly.
You can run only one generation process at time. In case you try to call again the /api/embeddings/generate API while a process is still ongoing, you will receive a 409 Conflict.
With this information, you have all the knowledge needed to generate the embeddings.
Generate embeddings from a webpage
From the API Portal you can make a request to the api/embeddings/generate API by expanding the corresponding card and clicking on "Try it out".
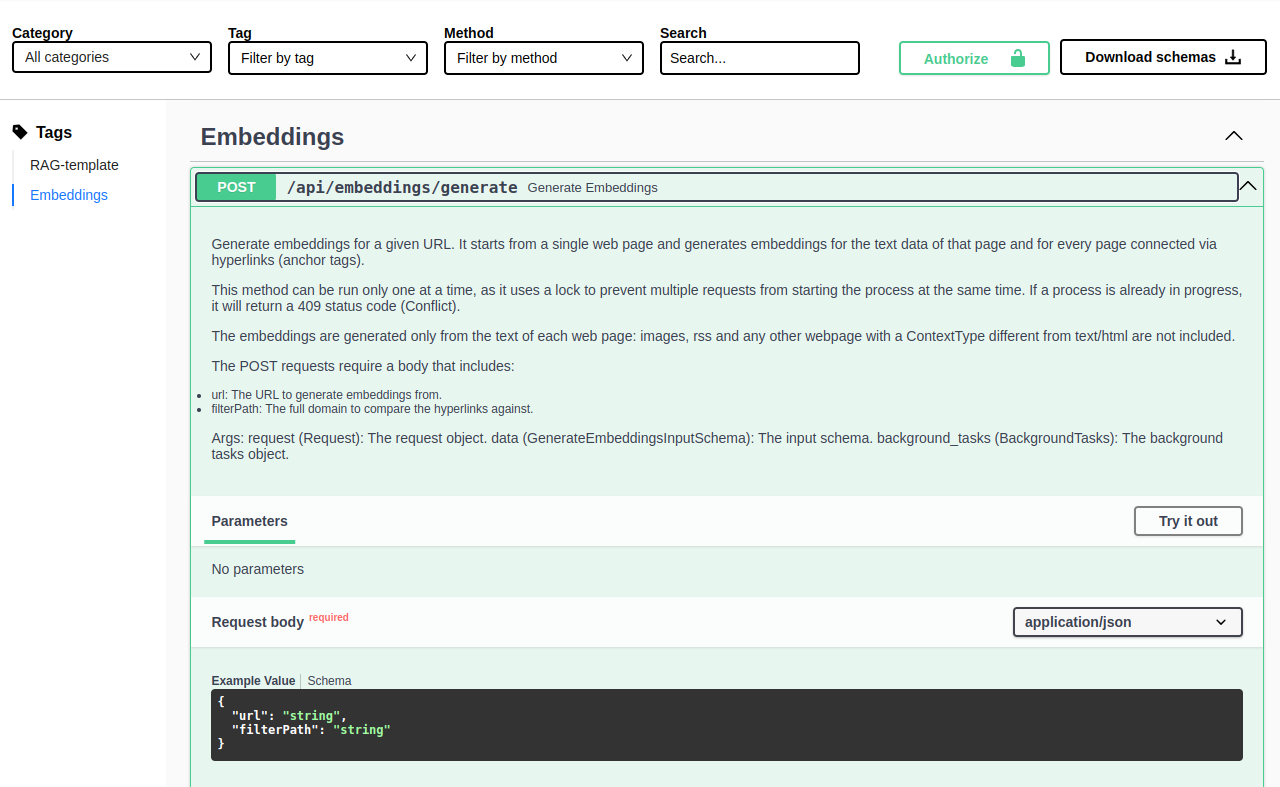
In the request body, the following information are needed:
url(mandatory): The starting page from which you want to generate embeddings.filterPath(optional): A more specific path that will be used as a filter when finding new pages to download and analyze.
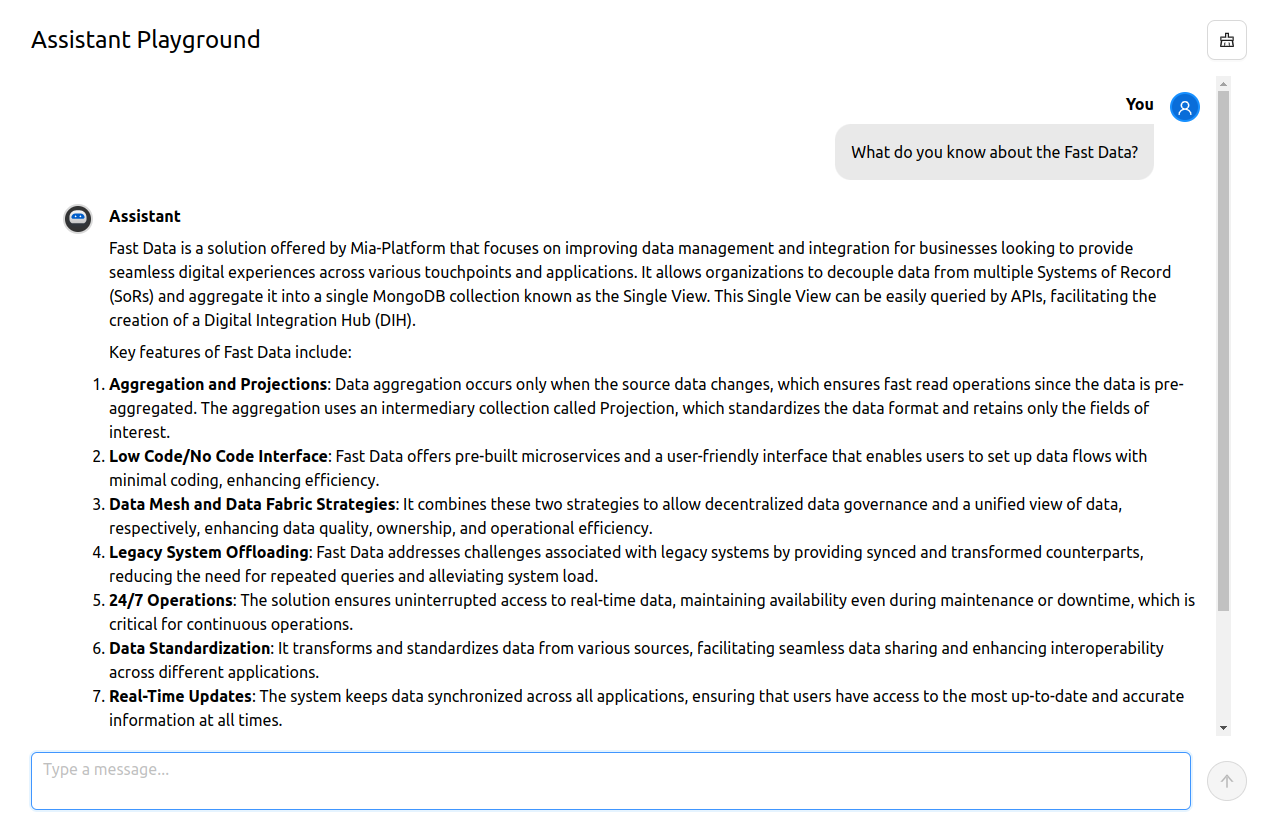
Let's try with part of the Mia-Platform documentation:
{
"url": "https://docs.mia-platform.eu/docs/fast_data/what_is_fast_data",
"filterPath": "https://docs.mia-platform.eu/docs/fast_data"
}
You can execute the same request via curl from your terminal with the following command:
curl -X POST "https://my-project.console.my-company.com/api/embeddings/generate" \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d "{ \"url\": \"https://docs.mia-platform.eu/docs/fast_data/what_is_fast_data\", \"filterPath\": \"https://docs.mia-platform.eu/docs/fast_data\" }"
A click on the Execute button and receive an immediate response indicating that the embedding generation has started.
At this point, it is simply needed to wait for the process to complete. To verify if the process is finished, you can send a request to the /api/embeddings/status API.
If the response body includes { "status": "running" }, it means that the webpages are still being scraped and embeddings are still being generated.
You can call the API multiple times, and when the response includes { "status": "idle" }, then the process is concluded.
Generate embeddings from a file
If you need to generate embeddings from a file, you can use to the api/embeddings/generateFromFile API, accessible from the API Portal.
By expanding the corresponding card and clicking on "Try it out", you will see that this time it is required to upload a file.
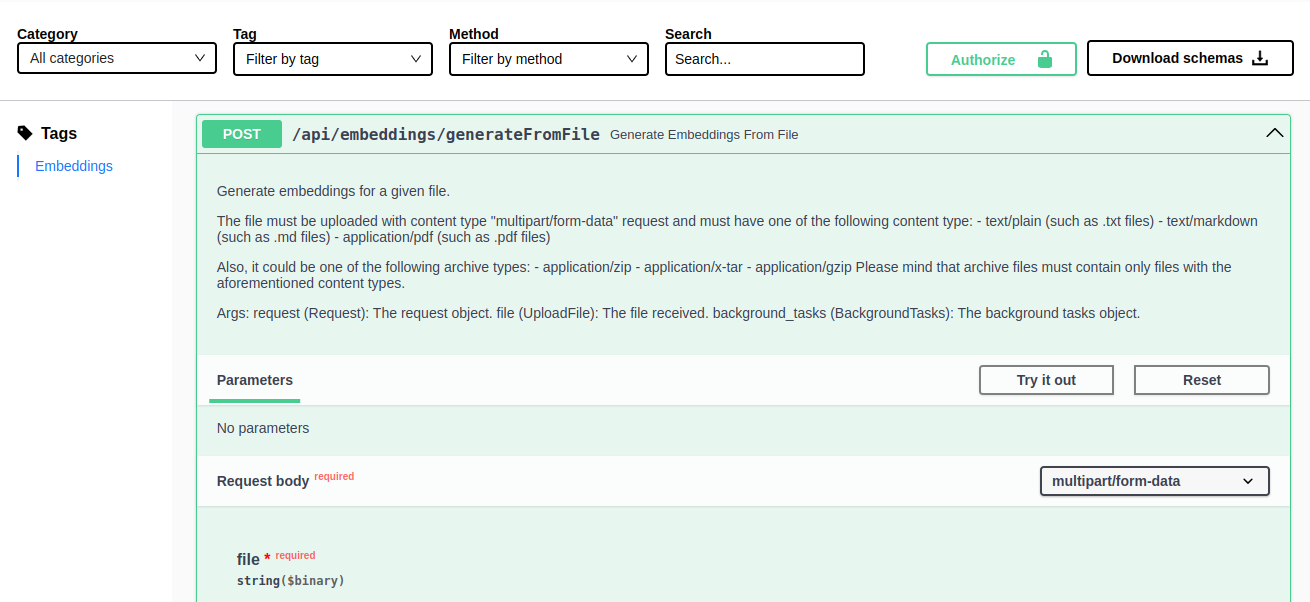
By clicking on Choose file you can select a file to upload. Supported files are the following:
- PDF files (
.pdf) - Text files (
.txt) - Markdown files (
.md) - Archive files (
.zip,.tar,.gz) that includes only PDF, text and markdown files
If you upload an archive file, please ensure that files contains only the required files in the root directory: other files or folders will be ignored.
After a click to the Execute button, the service will start the embedding generation process.
As explained above, you can check the status of the process by calling the /api/embeddings/status API until the response body includes { "status": "idle" }, meaning the process is concluded.
4. Enjoy
Once the process is over, there's no need to re-deploy or restart any service: after a few moments, the MongoDB Vector Index will be updated and the frontend application will be ready to give us meaningful answers based on the generated embeddings.
Troubleshooting
I have generated the embeddings, but the chatbot still does not answer correctly to my questions
Check the logs of the RAG Chatbot API. At the very beginning, it should say whether the MongoDB Vector Search Index has been created/updated or if it failed for any reason (e.g. database temporarily not accessible or the collection does not exists yet). In any case the service will start.
You may need to restart the service pod or manually create (or update) the index.
The frontend is not visible
Make sure you have correctly configured the ingress route, for example, with Traefik (you can refer to the documentation for more information on how to configure it).