Job Runner
Data Catalog Job Runner can trigger the execution of different jobs that can update the state of the Data Catalog solution.
The service keeps an internal queue where different requests sent by the Data Catalog UI are processed and executed, while collecting feedback that can be sent back to clients that need to obtain information about the status of the current jobs that are running.
Available Jobs
Here are listed the main jobs that the service can execute.
Agent Dataset Scan
Agent Dataset Scan is a procedure that queries datasources for the data schemas of the resources they own and stores them into the Data Catalog as documents compliant to the Open Lineage specification. The job provides facilities to:
- query tables schemas;
- aggregate them in a unique JSON format;
- store the resulting datasets into the MongoDb database of the Data Catalog application.
This job can be triggered by configuring a Connection from its section in the Data Catalog UI.
Odbc Connections
In the context of databases, it requires Open Database Connectivity (ODBC) drivers to connect to external DBMS. The service comes already equipped with the following ODBC drivers:
ODBC Driver 18 for SQL Server,MySQL ODBC 9.1 Unicode Driver,MySQL ODBC 9.1 ANSI Driver,MySQL ODBC 8.0 Unicode Driver,MySQL ODBC 8.0 ANSI Driver,PostgreSQL ANSI,PostgreSQL Unicode,Oracle 23 ODBC driver,Saphana HDBODBC
Data Catalog Sync
Data Catalog Sync is a procedure that is automatically scheduled after an Agent Dataset Scan job: its duty is to align the datasets retrieved previously by the Agent and convert theminto assets that can be managed by the Data Catalog application.
Connection Cleanup
Connection Cleanup is a set of procedures that are launched automatically when a user deletes a connection from the Data Catalog UI. These jobs will delete all assets related to a connection. In particular:
datasetsCleanupJob: will delete Open Lineage datasets linked to a connection;jobsCleanupJob: will delete all Jobs defined for the connection's datasets.
Fast Data Jobs Sync
Fast Data Jobs Sync is a procedure that generates Open Lineage Jobs from existing Fast Data pipelines of the Runtime Management.
This jobs can be linked to existing Mia Platform CRUD connections where the proper namespace details have been defined, so that they can be accessible from the Data Lineage section.
Starting from Job Runner v0.3.0, Fast Data automatic jobs are processed to expose on the Data Lineage UI not only the source code automatically retrieved from the pipeline configurations, but also the column lineage information retrieved from the imported source code parsing, compliant with the OpenLineage ColumnLineageDatasetFacet standard.
For more details on how to navigate and interpret this information, refer to the Column Lineage section.
If you have an instance of Data Catalog Application that is already running with a version of Job Runner prior to v0.3.0, in order to have the column lineage information available on the Data Lineage UI, you need to trigger the Fast Data Jobs Sync procedure for the existing pipelines. This operation will update the existing jobs with the new column lineage information.
Trigger Job
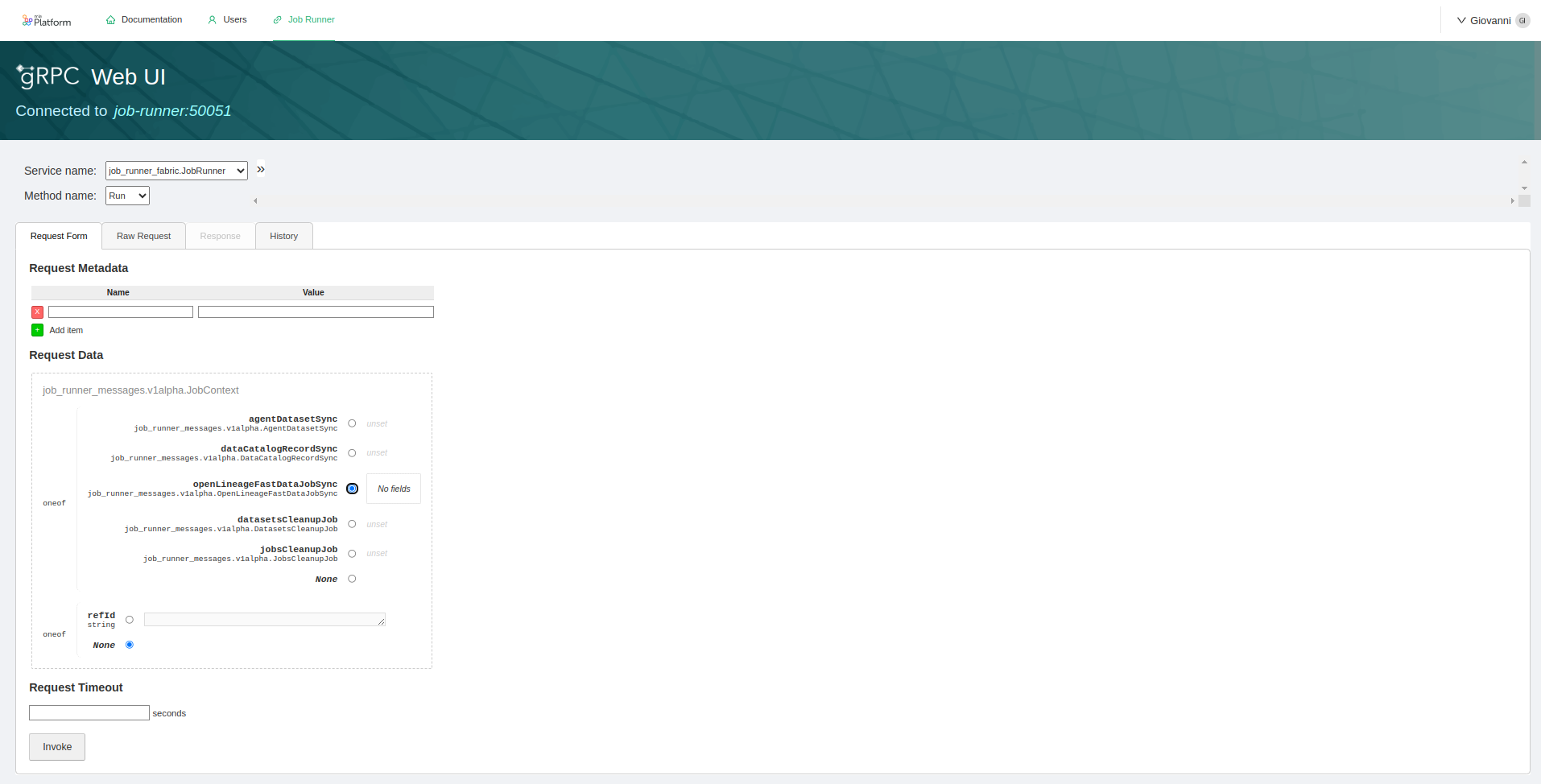
To launch the Fast Data Jobs Sync procedure you have to manually invoke the gRPC method.
Data Catalog Application is shipped with an already pre-configured grpcui,
that is exposed under proper permissions as part of the Secure Access microfrontend.
From there, you can pick the JobRunner service, choose the Run method and then pick the openLineageFastDataJobSync option as request.
You need also to specify the name of the producer as a string parameter: this information will be displayed in the Data Catalog UI Job Details section.
If you've already set up a Data Catalog Application that didn't have a grpcui microservice, you can create one with the following parameters:
- Docker Image Name:
fullstorydev/grpcui:v1.4.1; - Command Line Arguments:
-plaintext-base-path=/ui/job-runner-bind=0.0.0.0-connect-fail-fast=falsejob-runner:50051
- Container Ports:
- Port Name:
http - Port: 80
- Target Port: 8080
- Protocol:
TCP
- Port Name:
- Probe Types:
TCP
Finally, you can add the endpoint /ui/job-runner (with rewrite base path as /ui/job-runner) having the permissions defined in the Secure Access chapter.
Remember also to add admin:producers to the set of permissions.
Configuration
Environment Variables
Fabric BFF can be customized using the following environment variables:
| Name | Required | Description | Default Value |
|---|---|---|---|
GRPC_PORT | - | This variable determines the TCP port where the GRPC controller binds its listener | 50051 |
LOG_LEVEL | - | Specify the centralized application log level, choosing from options such as debug, error, info, trace or warn | info |
JOB_RUNNER_FOLDER | - | Set the location of the configuration files | ~/.fd/job-runner |
FAST_DATA_JOBS_FOLDER | - | Set the location of Fast Data Jobs Sync configuration file. | ~/.fd/fast-data-jobs |
ODBCINI | - | Optional full path where a custom .odbc.ini can be used to retrieve user defined data sources | ~/.fd/job-runner/.odbc.ini |
Main Configuration
The main configuration of the service is handled by a config.json, located at the path defined by the JOB_RUNNER_FOLDER.
When instantiating Data Catalog application, Job Runner service configuration is generated with
a dedicated Config Map, named job-runner-config. This file contains a template configuration that should help in configuring the service.
- Schema Viewer
- Raw JSON Schema
- Example
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Job Runner Configuration",
"type": "object",
"examples": [
{
"persistence": {
"type": "mongodb",
"configuration": {
"url": {
"type": "file",
"path": "/run/secrets/data-fabric/open-lineage.ini",
"key": "MONGODB_URL"
},
"database": "data-fabric-db"
}
}
}
],
"properties": {
"persistence": {
"anyOf": [
{
"$ref": "#/definitions/Persistence"
},
{
"type": "null"
}
]
}
},
"definitions": {
"MongodbPersistence": {
"type": "object",
"required": [
"url"
],
"properties": {
"database": {
"description": "Optional database name. It selects which database to be employed for storing data (it overrides the one provided in the connection string when it is set)",
"default": null,
"type": [
"string",
"null"
]
},
"url": {
"description": "MongoDB connection string",
"allOf": [
{
"$ref": "#/definitions/secret"
}
]
}
}
},
"Persistence": {
"oneOf": [
{
"type": "object",
"required": [
"configuration",
"type"
],
"properties": {
"configuration": {
"$ref": "#/definitions/MongodbPersistence"
},
"type": {
"type": "string",
"enum": [
"mongodb"
]
}
}
}
]
},
"secret": {
"oneOf": [
{
"type": "string"
},
{
"type": "object",
"required": [
"key",
"type"
],
"properties": {
"encoding": {
"type": "string",
"enum": [
"base64"
]
},
"key": {
"type": "string"
},
"type": {
"const": "env"
}
}
},
{
"type": "object",
"required": [
"path",
"type"
],
"properties": {
"encoding": {
"type": "string",
"enum": [
"base64"
]
},
"key": {
"type": "string"
},
"path": {
"type": "string"
},
"type": {
"const": "file"
}
}
}
]
}
}
}
{
"persistence": {
"type": "mongodb",
"configuration": {
"url": {
"type": "file",
"path": "/run/secrets/data-fabric/open-lineage.ini",
"key": "MONGODB_URL"
},
"database": "data-fabric-db"
}
}
}
In the paragraph below is explained how to configure the persistence layer.
Persistence Layer
Currently only MongoDB is supported as persistence layer for storing relevant data.
The MongoDB database selected for storing Data Catalog data must be configured to have replicaSet enabled, since
Job Runner exploits features that can be used only when a replicaSet is available.
In order to carry out all its operations, Job Runner requires a persistence layer where relevant information, such as auditing details, are stored. This configuration can be set under
the persistence.configuration key of the configuration file. The main properties are:
url→ the connection string to your MongoDB instance;database→ the database name where to search for the collections relevant to Job Runner service. Please notice that setting this property will override the database name potentially set in the connection string.
The following properties support secrets resolution:
persistence.configuration.urlpersistence.configuration.database
Fast Data Jobs Sync Configuration
Since the Fast Data Job Sync may need to retrieve Control Plane pipelines from a different database, it's also possible to provide an additional persistence configuration to
specify the databases to retrieve data. This optional configuration can be read from a config.json file located at the path defined by the FAST_DATA_JOBS_FOLDER environment variable.
- Schema Viewer
- Raw JSON Schema
- Example
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Fast Data Job Sync Configuration",
"type": "object",
"required": [
"controlPlane"
],
"examples": [
{
"controlPlane": {
"type": "mongodb",
"configuration": {
"url": "mongodb://<server>:27017/<default-database>?replicaSet=local",
"database": "<data-fabric-database-name>"
}
}
}
],
"properties": {
"controlPlane": {
"$ref": "#/definitions/ControlPlanePersistence"
}
},
"additionalProperties": false,
"definitions": {
"ControlPlanePersistence": {
"type": "object",
"required": [
"persistence"
],
"properties": {
"persistence": {
"$ref": "#/definitions/Persistence"
}
}
},
"MongodbPersistence": {
"type": "object",
"required": [
"url"
],
"properties": {
"database": {
"description": "Optional database name. It selects which database to be employed for storing data (it overrides the one provided in the connection string when it is set)",
"default": null,
"type": [
"string",
"null"
]
},
"url": {
"description": "MongoDB connection string",
"allOf": [
{
"$ref": "#/definitions/secret"
}
]
}
}
},
"Persistence": {
"oneOf": [
{
"type": "object",
"required": [
"configuration",
"type"
],
"properties": {
"configuration": {
"$ref": "#/definitions/MongodbPersistence"
},
"type": {
"type": "string",
"enum": [
"mongodb"
]
}
}
}
]
},
"secret": {
"oneOf": [
{
"type": "string"
},
{
"type": "object",
"required": [
"key",
"type"
],
"properties": {
"encoding": {
"type": "string",
"enum": [
"base64"
]
},
"key": {
"type": "string"
},
"type": {
"const": "env"
}
}
},
{
"type": "object",
"required": [
"path",
"type"
],
"properties": {
"encoding": {
"type": "string",
"enum": [
"base64"
]
},
"key": {
"type": "string"
},
"path": {
"type": "string"
},
"type": {
"const": "file"
}
}
}
]
}
}
}
{
"controlPlane": {
"type": "mongodb",
"configuration": {
"url": "mongodb://<server>:27017/<default-database>?replicaSet=local",
"database": "<data-fabric-database-name>"
}
}
}
The following properties support secrets resolution:
controlPlane.configuration.urlcontrolPlane.configuration.database
Secrets Names Configuration
To let the Data Catalog UI be aware of possible secret that can be used within connection definitions, the service can be additionally
configured with a secret.json file located at the JOB_RUNNER_FOLDER.
The configuration is a key-value pair JSON representation where:
- the keys represent the secret name that can be used by external services as reference when triggering a job. This name will be made available by the gRPC method
ListSecretNamesto the Data Catalog Frontend during Connection creation; - the values represent a secret (that can be represented according to Fast Data secret resolution).
- Schema Viewer
- Raw JSON Schema
- Example
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Secrets Configuration",
"type": "object",
"additionalProperties": {
"$ref": "#/definitions/secret"
},
"examples": [
{
"secretPlain": "{{MY_PLAIN_SECRET}}",
"secretEnv": {
"type": "env",
"key": "EXAMPLE_ENV"
},
"secretFile": {
"type": "file",
"path": "/run/secrets/job_runner/example.ini",
"key": "EXAMPLE_INI_KEY"
}
}
],
"definitions": {
"secret": {
"oneOf": [
{
"type": "string"
},
{
"type": "object",
"required": [
"key",
"type"
],
"properties": {
"encoding": {
"type": "string",
"enum": [
"base64"
]
},
"key": {
"type": "string"
},
"type": {
"const": "env"
}
}
},
{
"type": "object",
"required": [
"path",
"type"
],
"properties": {
"encoding": {
"type": "string",
"enum": [
"base64"
]
},
"key": {
"type": "string"
},
"path": {
"type": "string"
},
"type": {
"const": "file"
}
}
}
]
}
}
}
{
"secretPlain": "{{MY_PLAIN_SECRET}}",
"secretEnv": {
"type": "env",
"key": "EXAMPLE_ENV"
},
"secretFile": {
"type": "file",
"path": "/run/secrets/job_runner/example.ini",
"key": "EXAMPLE_INI_KEY"
}
}
When the service receives a request to trigger a job, it will first try to resolve the secrets contained in the request by looking at the entries of this file: if no secret can be found, the service will try to read the corresponding secret from the process environment.
ODBC Configuration
An ODBC connection can configured either by the means of Connection Strings or Data Source Names (DSN).
A Connection String is a string of key-value pairs where each of them represents a parameter of your connection.
Data Source Names (DSN) are symbolic names that can be linked to an ODBC connection. Job Runner service can read into a user-defined .odbc.ini file to load
at runtime the ODBC connections that can be executed through DSN. The list of available DSN then can be used by the Data Catalog UI while configuring an ODBC connection.
Job Runner reads DSN in its user-defined .odbc.ini located by default in the main configuration folder. To learn more about DSN and their connection parameters,
please refer to the official documentation.
Here are listed some example for the supported ODBC drivers:
Oracle
Job Runner needs additional configuration to run jobs towards Oracle databases.
With Oracle databases, connectivity can be handled with tnsnames.ora files and/or wallets.
TS Names
The service expects such assets in the Config Map located at /opt/oracle/instantclient/network/admin/, which must be checked to not overwrite the content of the whole folder.
Wallets
Oracle Wallet contains authentication and signal credentials of a database, which needs to be built with the whole service.
To add an oracle wallet to Job Runner service, you have to __replace the microservice container with a custom container located in your registry.
This custom container consists of a Dockerfile, which uses the Job Runner service as base layer and adds on top of it the desired wallets.
Once the custom wallets are copied into the container's /opt/oracle/instantclient/network/admin/, you can tune the sqlora.net file registering the path /opt/oracle/instantclient/network/admin/.
This path can be overridden by the means of the environment variable TNS_ADMIN.
FROM nexus.mia-platform.eu/data-fabric/job-runner:<latest version>
COPY <wallet location> /opt/oracle/instantclient/network/admin/
COPY <<EOF /opt/oracle/instantclient/network/admin/sqlora.net
WALLET_LOCATION = (SOURCE = (METHOD = file) (METHOD_DATA = (DIRECTORY="/opt/oracle/instantclient/network/admin"))) SSL_SERVER_DN_MATCH=yes
EOF
- Connection String
- DSN
The list of all the available connection parameters can be found in the official Oracle documentation.
driver=Oracle 23 ODBC driver;dbq=<SERVERNAME>;uid=<UID>;pwd=<PWD>;
Please note that dbq field can either be the an entry of your tsnames.ora file or an inline entry such as:
(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=0.0.0.0)(PORT=5041))(CONN ...))
Here's an example of a .odbc.ini file containing an Oracle DSN.
# 👇 change the placeholder with the name of your connection
[{CONNECTION NAME}]
AggregateSQLType=FLOAT
Application Attributes=T
Attributes=W
BatchAutocommitMode=IfAllSuccessful
BindAsFLOAT=F
CacheBufferSize=20
CloseCursor=F
# 👇 ...optional description
Description=
DisableDPM=F
DisableMTS=T
DisableRULEHint=T
Driver=Oracle 23 ODBC driver
EXECSchemaOpt=
EXECSyntax=T
Failover=T
FailoverDelay=10
FailoverRetryCount=10
FetchBufferSize=64000
ForceWCHAR=F
LobPrefetchSize=8192
Lobs=T
Longs=T
MaxLargeData=0
MaxTokenSize=8192
MetadataIdDefault=F
# 👇 ...db password credentials
Password=
QueryTimeout=T
ResultSets=T
# 👇 ...here goes the DBQ field of the connection string, or an entry name of a configured tsnames.ora
ServerName=
SQLGetData extensions=F
SQLTranslateErrors=F
StatementCache=F
Translation Option=0
UseOCIDescribeAny=F
# 👇 ...db username credentials
UserID=
PostgreSQL
- Connection String
- DSN
The list of all the available connection parameters can be found in the official documentation.
driver={PostgreSQL Unicode};server=<HOSTNAME>;port=5432;uid=<UID>;pwd=<PWD>;database=<DATABASE>;
Here's an example of a .odbc.ini file containing a PostgreSQL DSN.
; 👇 change the placeholder with your connection name
[{NAME}]
; 👇 here goes the name of the database you want to connect
Database=
; 👇 [optional] here goes the description of your connection
Description=
Driver=PostgreSQL Unicode
Port=5432
; 👇 database host location
ServerName=
; 👇 database username
Username=
; 👇 database password
Password=
MySQL
- Connection String
- DSN
The list of all the available connection parameters can be found in the official documentation.
driver={MySQL ODBC 9.1 Unicode Driver};server=<HOSTNAME>;port=5432;uid=<UID>;pwd=<PWD>;database=<DATABASE>;
Here's an example of a .odbc.ini file containing a MySQL DSN. (for more details, refer to the official documentation)
; 👇 change the placeholder with your connection name
[{NAME}]
Driver=MySQL ODBC 9.1 Unicode Driver
; 👇 here goes the port of your database (if not specified, defaults to 3306)
Port=
; 👇 here goes the name of the database you want to connect
Database=
; 👇 database host location
Server=
; 👇 database username
Username=
; 👇 database password
Password=
MSSQL
You can refer to the official documentation for a list of all the supported parameters.
- Connection String
- DSN
Driver={ODBC Driver 18 for SQL Server};Server=<HOSTNAME>;Database=<DBNAME>;Uid=<USERNAME>;Pwd=<PWD>;TrustServerCertificate=yes
Here's an example of a .odbc.ini file containing a MSSQL DSN. Username and password must be provided from the Data Catalog UI.
; 👇 change the placeholder with your connection name
[{NAME}]
Driver=ODBC Driver 18 for SQL Server
; 👇 here goes the name of the database you want to connect
Database=
; 👇 write in the form of "tcp:<hostname>,<port number>"
Server=
; 👇 enable self-signed encryption
TrustServerCertificate=yes
SAP HANA
- Connection String
- DSN
You can refer to the official documentation for a list of all the supported parameters.
Driver={Saphana HDBODBC};ServerNode=<HOSTNAME>:<PORT>;DatabaseName=<DBNAME>;UID=<USERNAME>;PWD=<PWD>;
Here's an example of a .odbc.ini file containing a SAP HANA DSN. Username and password must be provided from the Data Catalog UI.
; 👇 change the placeholder with your connection name
[{NAME}]
Driver=Saphana HDBODBC
; 👇 here goes the name of the database you want to connect
DatabaseName=
; 👇 write in the form of "<hostname>:<port number>"
ServerNode=
gRPC Services
The request exchanged between Fabric BFF and Job Runner services are performed through gRPC.
Thus, on Job Runner service is necessary to advertise the port where the gRPC controller is exposed, which by default is the 50051.
This operation can be achieved by setting the proper port to the list of Container Ports
that can be found in the Console Design area, under the specific microservice resource.
When instantiating Data Catalog application, Container Ports are pre-filled with all the needed ports using their default value. In case the gRPC port chosen through environment variables has been edited, please change the Container Ports accordingly.
Here are listed the main services that are exposed by the service.
ODBC Client
Service responsible to retrieve information about the status of the ODBC driver. It has the following methods:
ListDrivers: unary RPC returning the list of drivers configured within the service;ListDataSources: unary RPC returning the list of data sources configured within the service.
Configuration
Service responsible to retrieve information about the main configuration of the service. It has the following methods:
ListSecretNames: unary RPC returning the names of secrets configured in the Secret Names Configuration section.
Job Runner
Service responsible to interact with the JobRunner service. It has the following methods:
Run: unary RPC that receive the context of a job and executes it, returning the corresponding identifier;Abort: unary RPC that, given a job id, stops the execution of a job currently executed by the service;List: unary RPC returning the list of jobs that are currently executed by the service;History: unary RPC returning the list of jobs that have been executed by the service;Status: server streaming RPC returning feedback messages from the active jobs.
Migration Guides
From Data Catalog Agent 0.6.x or 0.7.x
Job Runner allows to run Data Catalog Agent via scheduling instead of a kubernetes cronjob.
Connections, previously configured on Data Catalog Agent, have a 1-to-1 mapping on Job Runner data catalog agent sync jobs.
The following features are NOT supported anymore:
- connection via custom Data Catalog Agent configuration (only connection-string and DSN allowed).
settings.connectionNameparameter.target.
Migrate a custom configuration
A Data Catalog Agent connection is a key/value pair
{
"my-connection": {
"type": "odbc",
"configuration": {
"vendor": "oracle",
...
}
}
}
and the Connections UI maps the key to the connection's name while the rest of the configuration is identical in case of a connection string.
When not using connection strings but Data Catalog Agent custom, per-vendor, configuration, the connection string must be extracted from those parameters.
MS SQL Server
The connection string must be in the form
Driver={};Server={},{};Database={};Uid={};Pwd={};{}
Driver must be one of the supported MS SQL Server drivers.
Server is a comma separated string formatted as <IP>,<PORT>. Database is the name of the remote catalog/schema. Uid and Pwd are the user credentials.
Any additional flag must be a trailing semi-colon separated list of attributes.
We recommend to store the connection string as a secret in the Job Runner and reference it via UI
The other supported connection is via DSN names
MySQL
The connection string must be in the form
DRIVER={};SERVER={};PORT={};DATABASE={};UID={};PWD={};{}
DRIVER must be one of the supported MySQL drivers as reported by the compatibility matrix.
SERVER is the IP or Domain name of the database while PORT the socket port. DATABASE is the name of the remote catalog/schema. UID and PWD are the user credentials.
Any additional flag must be a trailing semi-colon separated list of attributes.
We recommend to store the connection string as a secret in the Job Runner and reference it via UI
The other supported connection is via DSN names
Oracle
The connection string must be in the form
DRIVER={};UID={};PWD={};DBQ={};{}
DRIVER must be one of the supported Oracle drivers.
UID and PWD are the user credentials. DBQ is the reference of a name specified in the tnsnames.ora file (or inline).
Any additional flag
must be a trailing semi-colon separated list of attributes.
We recommend to store the connection string as a secret in the Job Runner and reference it via UI
The other supported connection is via DSN names
PostgreSQL
The connection string must be in the form
DRIVER={};SERVER={};PORT={};DATABASE={};UID={};PWD={};{}
DRIVER must be one of the supported PostgreSQL drivers.
SERVER is the IP or Domain name of the database while PORT the socket port. DATABASE is the name of the remote catalog/schema. UID and PWD are the user credentials.
Any additional flag must be a trailing semi-colon separated list of attributes.
We recommend to store the connection string as a secret in the Job Runner and reference it via UI
The other supported connection is via DSN names
PostgreSQL
The connection string must be in the form
driver={};serverNode={}:{};databaseName={};UID={};PWD={};{}
DRIVER must be one of the supported PostgreSQL drivers.
serverNode is in the format <IP>:<PORT>. databaseName is the name of the remote catalog/schema. UID and PWD are the user credentials.
Any additional flag must be a trailing semi-colon separated list of attributes.
We recommend to store the connection string as a secret in the Job Runner and reference it via UI
The other supported connection is via DSN names
Migrate settings.connectionName
Use the value directly in the Connections UI connection name.
Targets
Within Data Catalog the mia-open-lineage target is the only one allowed and auto-configured from the Job Runner persistence layer.